ebpf/sockhash 内核bug定位分析
背景
最近在尝试使用bpf来优化istio场景下本地sidecar和app之间的数据传输,使用了ebpf/sockhash的特性。简单来讲,如果一台机器上有两个进程的sock存在相互收发数据的情况,我们就可以利用ebpf/sockhash将一个socket需要发送的数据跳过本机的底层tcp/ip协议栈直接交给本机的目的socket,缩短数据在内核的处理路径。
在测试过程中,我们发现一般的场景下网络都没有问题,数据包也确实跳过了协议栈直接转发给了对端的socket,但是当我们通过python -m SimpleHTTPServer启动一个server并通过curl访问时,发现大概率出现错误 curl: (52) Empty reply from server;如果通过curl从server下载一个稍大的文件,也经常出现下载不全的情况,且每次下载下来文件的大小不固定。但是这个情况只在 SimpleHTTPServer 中能复现,我尝试自己写一个go http server来传输数据下载文件发现都没有问题。难道是 SimpleHTTPServer 这个模块有什么特殊性?
通过tcpdump抓包,我们发现在python server中,在服务器端发送完数据后,就直接发送了FIN包。
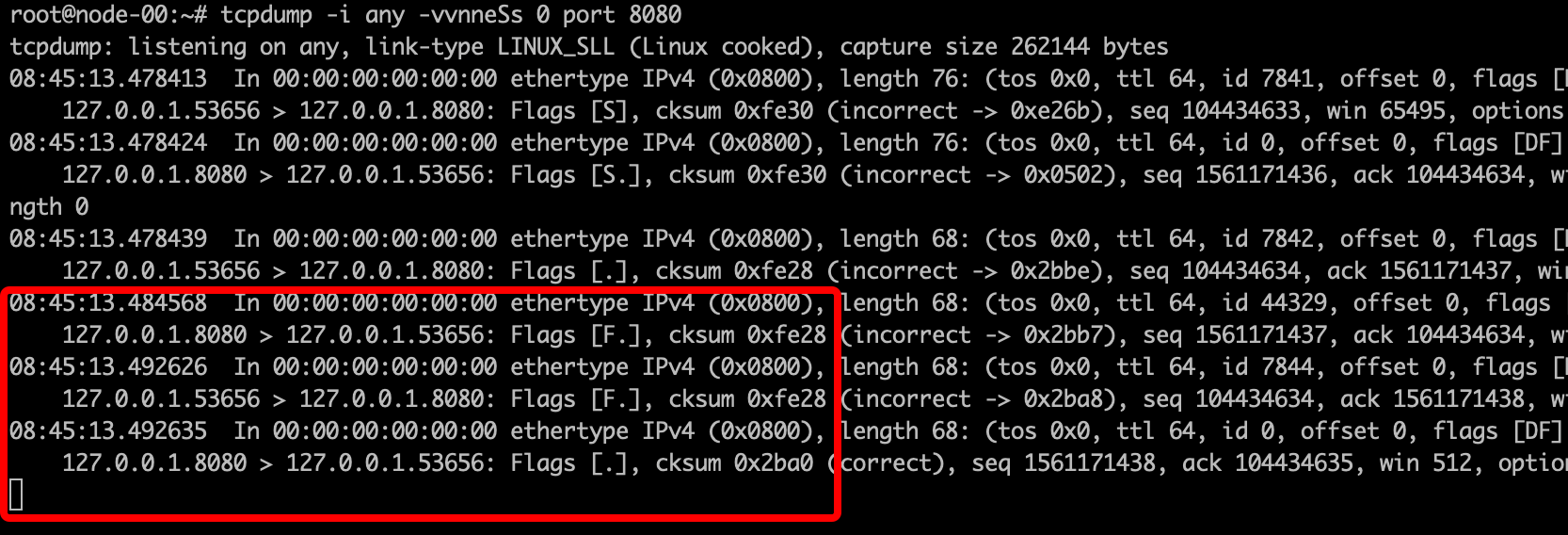
而对比无异常的服务,都是client在收完server包后先发送的FIN包,server收到FIN后再向client发起的FIN包。原来通过python自带模块起的http server只支持http1.0 协议,导致server端发完数据后即发送了FIN包。
在排除我们的程序有异常的情况下,怀疑内核本身在这一块对数据的处理可能存在bug, 尤其是收到FIN包之后的处理,可能收到FIN包后忽略了一些转发数据的处理。
bug定位
sockhash实际上是bpf中的一种特殊的map类型,存储的kv数据中value的类型实际是对应一个sock。除了存储sock,这类map上还可以attach一个用户编写的sk_msg类型的bpf程序来查找接收数据的socket。
在这里,我们通过attach一种sock_ops类型的bpf函数到cgroupv2的根路径,使得在发生一些socket事件(例如建立连接)时,通过这个bpf函数将sock对象放入到sockhash中。 将sock存储到sockhash时,内核会调用net/core/sock_map.c中的sock_hash_update_common函数,在这个函数中,会更新socket接收数据和发送数据的函数,将原先的 tcp_recvmsg/tcp_sendmsg 替换成 tcp_bpf_recvmsg/tcp_bpf_sendmsg 。重写的方法如下,其中的base就是默认的tcp_proto:1
2
3
4
5
6
7
8
9
10
11
12
13static void tcp_bpf_rebuild_protos(struct proto prot[TCP_BPF_NUM_CFGS],
struct proto *base)
{
prot[TCP_BPF_BASE] = *base;
prot[TCP_BPF_BASE].unhash = tcp_bpf_unhash;
prot[TCP_BPF_BASE].close = tcp_bpf_close;
prot[TCP_BPF_BASE].recvmsg = tcp_bpf_recvmsg;
prot[TCP_BPF_BASE].stream_memory_read = tcp_bpf_stream_read;
prot[TCP_BPF_TX] = prot[TCP_BPF_BASE];
prot[TCP_BPF_TX].sendmsg = tcp_bpf_sendmsg;
prot[TCP_BPF_TX].sendpage = tcp_bpf_sendpage;
}
在sock准备发送数据时,首先就会调用tcp_bpf_sendmsg。在tcp_bpf_sendmsg中,调用tcp_bpf_send_verdict,然后调用sk_psock_msg_verdict。而在sk_psock_msg_verdict中,会执行我们之前attach到sockhash上的用户自定义bpf程序。在这个BPF程序中,我们会根据发送者sock信息构造一个key值,然后调用msg_redirect_hash通过传入的key值来找到接收者的sock信息,将其存入当前sock的psock的sk_redir中。注意,虽然我们在bpf程序中调用的函数叫msg_redirect_hash, 但是实际上这个函数只是会负责根据key来找到接受方sock。执行完bpf程序拿到接收方sock信息后内核才负责调用tcp_bpf_sendmsg_redir(sk_redir, msg),将数据放入sk_redir的psock->ingress_msg这个queue中,最后通知对端sock数据已经ready了(通过回调函数sk->sk_data_ready,实际调用sock_def_readable)。接收方sock此时再通过tcp_bpf_recvmsg从ingress_msg中读取数据。
为了定位内核问题,我们在我们的bpf程序中加了点log来打印发送端发送数据的大小,并通过内核提供的tracing手段kretprobe打印tcp_bpf_recvmsg的返回值来查看实际收到的数据。1
2
3
4cd /sys/kernel/debug/tracing/
echo 'r:kprobes/myretprobe tcp_bpf_recvmsg ret=$retval' > kprobe_events
echo 1 > events/kprobes/enable
cat trace_pipe
在无异常情况下,我们可以看到下图的结果。
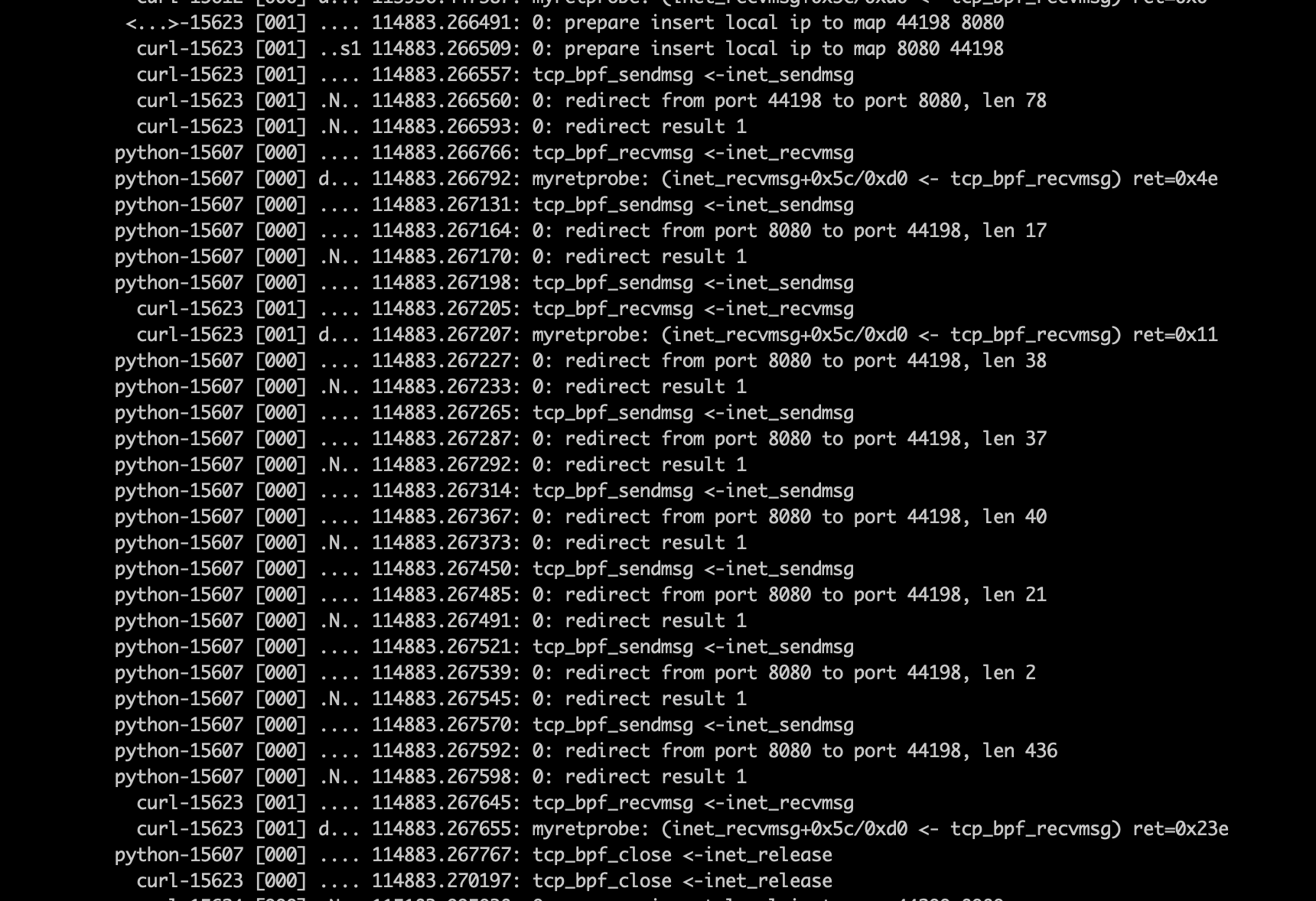
可以看到,在正常情况下,tcp_bpf_recvmsg的返回值是0x23e=574, 等于发送端发送的数据总和。
而在异常情况下,我们看到的结果如下
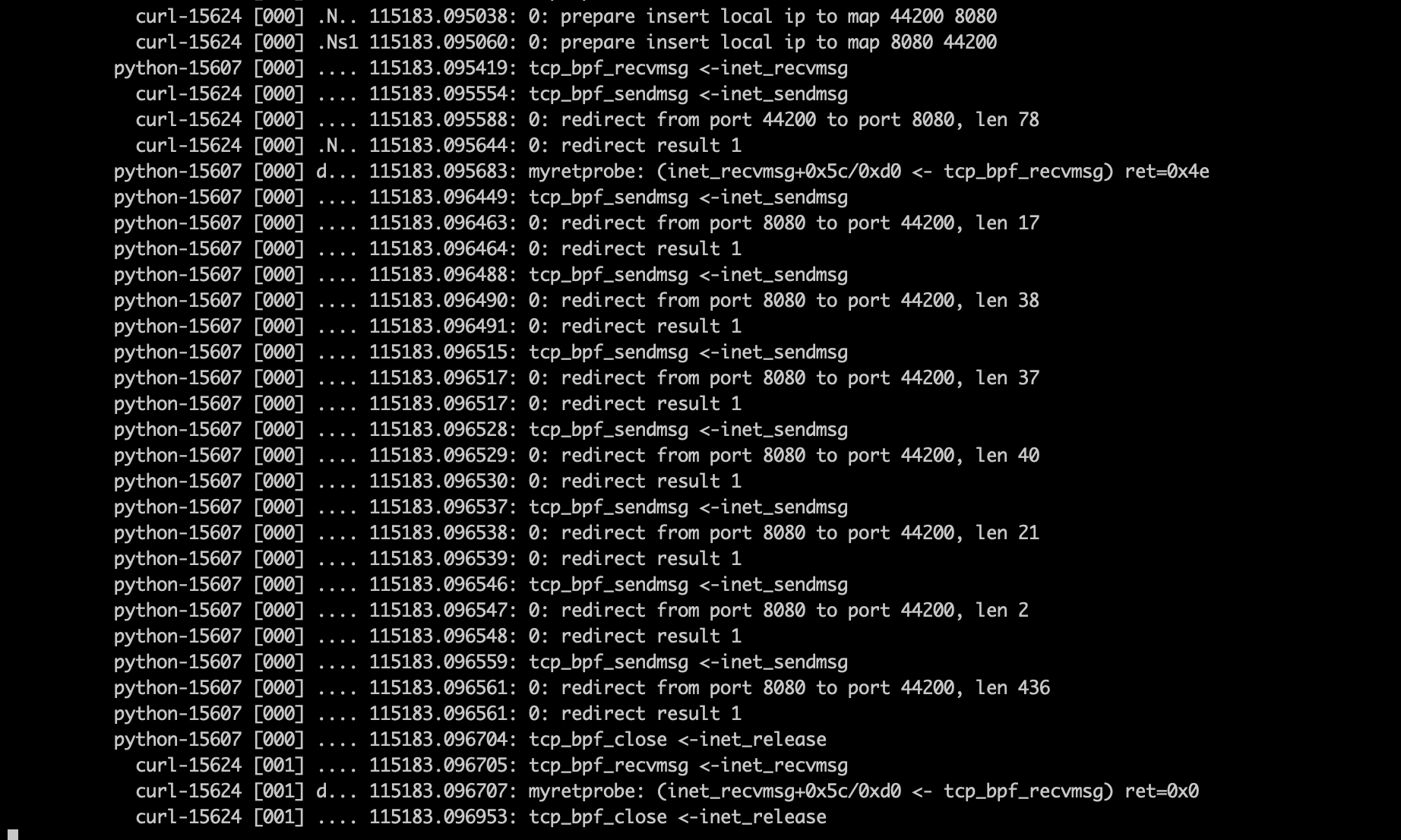
可以看到,虽然发送方发送了多组数据,但是tcp_bpf_recvmsg返回值是0,说明在此次读取中,并没有读到数据。
为了搞清楚此时tcp_bpf_recvmsg的执行情况,使用ftrace提供的graph_function trace功能,打印出了tcp_bpf_recvmsg下函数的的调用情况1
2
3
4
5cd /sys/kernel/debug/tracing/
echo tcp_bpf_recvmsg > set_graph_function
echo 3 > max_graph_depth
echo function_graph > current_tracer
cat trace_pipe
可以看到,进入tcp_bpf_recvmsg后直接调用了tcp_recvmsg函数,结合tcp_bpf_recvmsg的源码:
1 | int tcp_bpf_recvmsg(struct sock *sk, struct msghdr *msg, size_t len, |
可以看到共有3出可能出现调用tcp_recvmsg,首先可以排除第3处的调用,因为如果是在第3处执行的,那么必然会先调用__tcp_bpf_recvmsg,而在ftrace中我们并没有发现对__tcp_bpf_recvmsg的调用。由于前面怀疑是因为FIN包的出现导致未能正常处理由tcp_bpf_sendmsg转发的包,所以怀疑是这里是因为第1处触发的tcp_recvmsg,也就是sk_receive_queue不为空。为了证实这个猜想,我们希望能通过tracing的手段来确认。由于对kprobe功能不是很熟悉,不知如何才能确定,这时候就用上了bpf的krpobe tracing功能。通过编写bpf程序并attack到tcp_bpf_recvmsg上,我们可以获取到sock对象并由此来判断sk_receive_queue。通过iovisor/bcc, 可以通过编写python代码来方便的操作bpf程序,bpf源码如下:1
2
3
4
5
6
7int hello_bpf_recv(struct pt_regs *ctx) {
struct sock *sk = (struct sock *)PT_REGS_PARM1(ctx);
struct sk_psock *psock;
u32 l = sk->sk_receive_queue.qlen;
bpf_trace_printk("Hello, sk_receive_queue len is %d!\\n", l);
return 0;
}
重新执行后,发现果然打印出来了len为1,基本验证了之前的猜想。当然,我们还可以进一步通过bpf程序验证一下这个queue里面的包是不是一个FIN包。通过跟踪内核代码,我们可以大概定位tcp_data_queue这个函数会将收到的包发如到这个queue中,我们可以在这个函数上attack一个bpf/kprobe程序,完整的程序在这里:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25int hellp_tcp_data_queue(struct pt_regs *ctx) {
struct sk_buff *skb = (struct sk_buff *)PT_REGS_PARM2(ctx);
u16 sport = 0, dport = 0;
struct tcphdr *tcp = skb_to_tcphdr(skb);
sport = tcp->source;
dport = tcp->dest;
sport = ntohs(sport);
dport = ntohs(dport);
if (sport == 8080 || dport == 8080) {
u8 tcpflags = ((u_int8_t *)tcp)[13];
u32 seq = tcp->seq;
seq = ntohl(seq);
bpf_trace_printk("tcp_data_queue for 8080, seq %u\\n", seq);
if (tcpflags & 0x01) {
bpf_trace_printk("tcp_data_queue get fin\\n");
}
if (tcpflags & 0x02) {
bpf_trace_printk("tcp_data_queue get syn\\n");
}
if (tcpflags & 0x10) {
bpf_trace_printk("tcp_data_queue get ack\\n");
}
}
return 0;
}
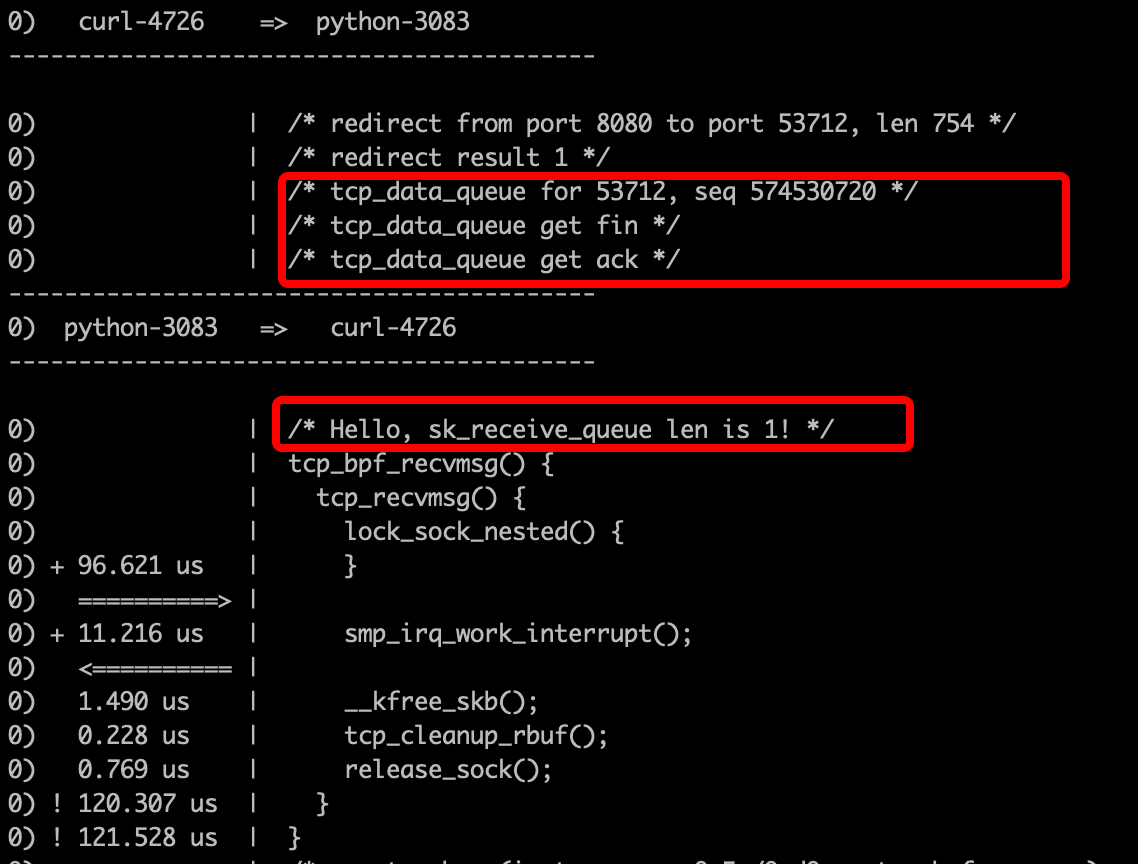
可以看到trace_pipe中可以打印出收到了FIN包
问题到这里基本就定位结束了,可以基本确定在收到FIN包后,client端认为server端已经没有数据可以读取了,所以直接通过sockhash redirect机制传输的存储在psock->ingress_msg中的数据还没有被读取完就释放了。
解决方案
可以看到,目前的逻辑是,当收到FIN包时会存储到sk_receive_queue中,tcp_bpf_recvmsg会优先从这里拿数据。一旦拿到FIN包,内核认为对端socket已经没有数据需要读取了,就不会再从ingress_msg里读数据了,但是数据未完全读完。
所以这里提出的解决方案也比较简单粗暴,修改tcp_bpf_recvmsg,如果有ingress_msg有数据,优先读取ingress_msg里的数据。
目前该patch已经被社区接受并合并到了内核bpf repo中,可在这里查看该patch。