ebpf intro
eBPF简介
eBPF(extended BPF)可以看作是可以高效且安全的在内核的一些hook point上执行用户代码的一个虚拟机,用户编写的代码被编译成字节码后加载到linux内核,内核内嵌了一个JIT将字节码转成native code后由事件触发形式执行BPF代码。eBPF由BPF发展而来,BPF全称Berkeley Packet Filter,当时主要是为了高效的过滤数据包而设计的,其历史可以追溯到1992年的论文The BSD Packet Filter: A New Architecture for User-level Packet Capture中。现在大家说到的BPF实际上是e(extended)BPF,相比于之前的BPF,eBPF是RISC指令集,有了更丰富的指令,11个64位的寄存器。开发者可以使用C语言写BPF程序,然后使用llvm+clang编译成bpf格式的obj file。然后通过bpf()系统调用加载在内核中hook point。下文中提到的BPF如果没有明确说明,都是指代eBPF。
在BPF出现之前,如果要抓包,需要使用tap工具将所有的包先拷贝到用户态然后使用匹配规则(并不高效的算法)去过滤拿到满足条件的包,而BPF可以将匹配算法在内核执行,不需要全量拷贝数据包到用户空间,且匹配算法更加高效,使得其相对于tap有更高的效率。虽然大家可能不熟悉BPF,但是linux下大名鼎鼎的抓包工具tcpdump即是基于这项技术实现的。
在介绍eBPF之前,我们先提前感受一下tcpdump中BPF的痕迹。tcpdump中有一个-d参数,Dump the compiled packet-matching code in a human readable form to standard output and stop.,用这个参数可以查看用户输入的匹配规则对应的bpf指令,例如1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21# tcpdump -i eth1 -d tcp and port 22
(000) ldh [12] # load half-byte to [x],读取3层协议号
(001) jeq #0x86dd jt 2 jf 8 # 如果是IPv6,则根据IPv6检查包
(002) ldb [20]
(003) jeq #0x6 jt 4 jf 19
(004) ldh [54]
(005) jeq #0x16 jt 18 jf 6
(006) ldh [56]
(007) jeq #0x16 jt 18 jf 19
(008) jeq #0x800 jt 9 jf 19 # 判断是否为IPv4协议
(009) ldb [23] # 加载4层协议号
(010) jeq #0x6 jt 11 jf 19 # TCP协议号
(011) ldh [20] # 加载 Flags和Fragment Offset
(012) jset #0x1fff jt 19 jf 13 # (前3bit是Flag)检测Fragment Offset 如果是IP分片,return 0
(013) ldxb 4*([14]&0xf) # 加载 ip header的length
(014) ldh [x + 14] # 加载src port
(015) jeq #0x16 jt 18 jf 16 # = 22
(016) ldh [x + 16] # 加载dst port
(017) jeq #0x16 jt 18 jf 19 # = 22
(018) ret #262144 # match
(019) ret #0 # not match
tcpdump转化的指定是cBPF(classic),可以看作是eBPF出现之前的BPF。只是在较新的内核(v3.15之后)中,内核支持eBPF,所以有专门的程序会负责将cBPF指令翻译成eBPF指令来执行。
可以看出,tcpdump的规则被翻译成了20条指令,数据包仅仅被看作是字节的数组,指令对从数据包(数组)的不同位置读取(load)数据到寄存器并判断是否满足条件,最后返回。
tcpdump使用的实际上是传统的BPF(cBPF),而较新的内核中除了支持cBPF,主要是对eBPF的支持。功能上eBPF相对于cBPF已经做了很大的扩展。目前最新的内核代码中已经有20+类不同的BPF程序类型,根据不同的程序类型,从最初的相对单一的网络包过滤,扩展出了一个通用的内核虚拟机,可以将BPF程序附着到tracepoint/kprobe/uprobe/USDT,可以支持seccomp,扩展更多的网络功能例如配合tc完成更多的数据包处理能力,使用XDP提升网络性能等。从指令集来看,相对于cBPF,eBPF有更丰富的指令集,支持了更多的寄存器。此外,还引入了helper functions和maps。不同版本内核支持的BPF特性可以参考这里。
prog type
每个BPF程序都属于某个特定的程序类型,目前内核支持20+不同类型的BPF程序类型,可以大致分为网络,跟踪,安全等几大类,BPF程序的输入参数也根据类型有所不同。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28enum bpf_prog_type {
BPF_PROG_TYPE_UNSPEC,
BPF_PROG_TYPE_SOCKET_FILTER,
BPF_PROG_TYPE_KPROBE,
BPF_PROG_TYPE_SCHED_CLS,
BPF_PROG_TYPE_SCHED_ACT,
BPF_PROG_TYPE_TRACEPOINT,
BPF_PROG_TYPE_XDP,
BPF_PROG_TYPE_PERF_EVENT,
BPF_PROG_TYPE_CGROUP_SKB,
BPF_PROG_TYPE_CGROUP_SOCK,
BPF_PROG_TYPE_LWT_IN,
BPF_PROG_TYPE_LWT_OUT,
BPF_PROG_TYPE_LWT_XMIT,
BPF_PROG_TYPE_SOCK_OPS,
BPF_PROG_TYPE_SK_SKB,
BPF_PROG_TYPE_CGROUP_DEVICE,
BPF_PROG_TYPE_SK_MSG,
BPF_PROG_TYPE_RAW_TRACEPOINT,
BPF_PROG_TYPE_CGROUP_SOCK_ADDR,
BPF_PROG_TYPE_LWT_SEG6LOCAL,
BPF_PROG_TYPE_LIRC_MODE2,
BPF_PROG_TYPE_SK_REUSEPORT,
BPF_PROG_TYPE_FLOW_DISSECTOR,
BPF_PROG_TYPE_CGROUP_SYSCTL,
BPF_PROG_TYPE_RAW_TRACEPOINT_WRITABLE,
BPF_PROG_TYPE_CGROUP_SOCKOPT,
};
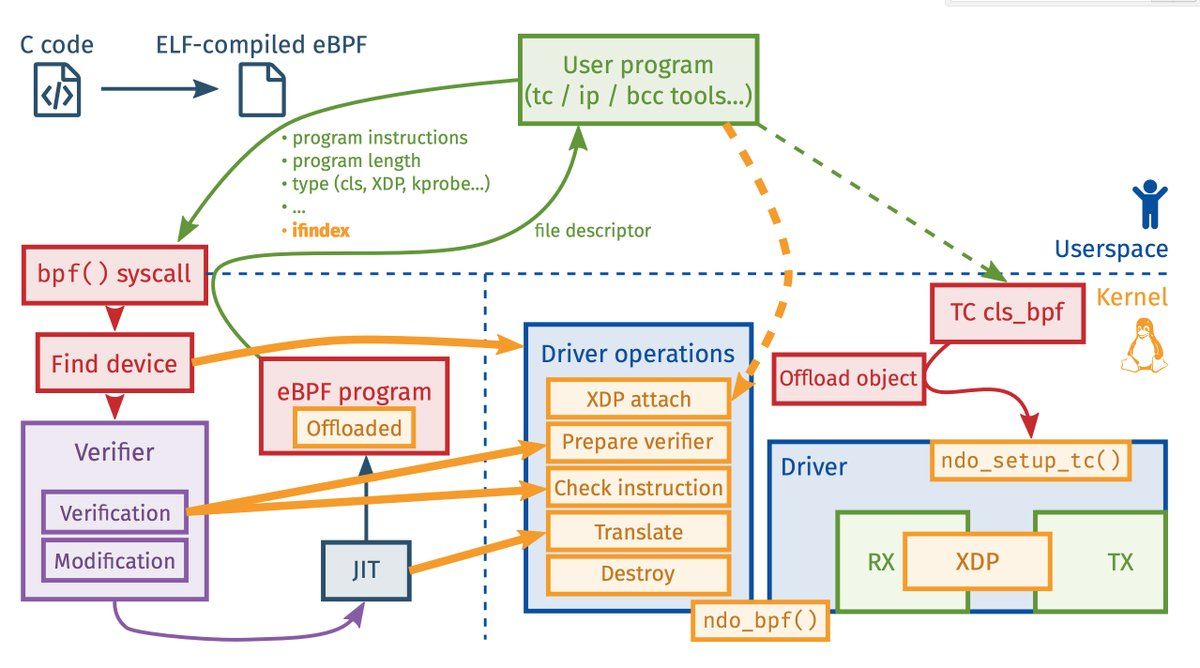
例如,BPF_PROG_TYPE_KPROBE BPF_PROG_TYPE_TRACEPOINT 等属于追踪。BPF_PROG_TYPE_XDP程序用于将BPF程序offload到driver层,在包刚从网卡上接收还未构造成skb之前,即执行BPF代码,效率相比于其他hook点要高,目前已有一些公司用XDP来抵御DDoS攻击,XDP具体使用方式以后再做详细介绍。BPF_PROG_TYPE_SOCK_OPS支持给socket设置一些TCP参数。BPF_PROG_TYPE_SK_MSG程序可以在socket调用sendmsg系统调用时被执行。
不同的程序类型挂载的方式有所不同,例如BPF_PROG_TYPE_SOCK_OPS程序可以使用BPF_CGROUP_SOCK_OPS方式将程序挂载到cgroup上,属于这个cgroup下的socket会执行程序。BPF_PROG_TYPE_SK_MSG可以以BPF_SK_MSG_VERDICT的方式挂载到某些特殊的map上,记录在map里的socket会调用BPF程序。
helper functions
helper functions是提供给BPF程序使用的辅助函数,BPF程序通常无法直接访问内核数据,所以提供了helper functions,通过这些函数完成一些辅助工作,比如从内核获取数据,操作内核的对象。
不同的BPF程序类型可以使用部分的辅助函数,例如XDP(BPF_PROG_TYPE_XDP)类型程序能使用的辅助函数在这里定义。
maps
maps是BPF程序中驻留在内核中存储 key/value 数据的存储方式的统称,实际上BPF提供了很多类型的map,很多map类型都有一些特殊的使用方式。BPF程序可以通过helper function读写map,用户态程序也可以通过bpf(...)系统调用读写map,因此可以通过map来达到BPF程序之间,BPF程序与用户态程序之间的数据交互与控制。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28enum bpf_map_type {
BPF_MAP_TYPE_UNSPEC,
BPF_MAP_TYPE_HASH,
BPF_MAP_TYPE_ARRAY,
BPF_MAP_TYPE_PROG_ARRAY,
BPF_MAP_TYPE_PERF_EVENT_ARRAY,
BPF_MAP_TYPE_PERCPU_HASH,
BPF_MAP_TYPE_PERCPU_ARRAY,
BPF_MAP_TYPE_STACK_TRACE,
BPF_MAP_TYPE_CGROUP_ARRAY,
BPF_MAP_TYPE_LRU_HASH,
BPF_MAP_TYPE_LRU_PERCPU_HASH,
BPF_MAP_TYPE_LPM_TRIE,
BPF_MAP_TYPE_ARRAY_OF_MAPS,
BPF_MAP_TYPE_HASH_OF_MAPS,
BPF_MAP_TYPE_DEVMAP,
BPF_MAP_TYPE_SOCKMAP,
BPF_MAP_TYPE_CPUMAP,
BPF_MAP_TYPE_XSKMAP,
BPF_MAP_TYPE_SOCKHASH,
BPF_MAP_TYPE_CGROUP_STORAGE,
BPF_MAP_TYPE_REUSEPORT_SOCKARRAY,
BPF_MAP_TYPE_PERCPU_CGROUP_STORAGE,
BPF_MAP_TYPE_QUEUE,
BPF_MAP_TYPE_STACK,
BPF_MAP_TYPE_SK_STORAGE,
BPF_MAP_TYPE_DEVMAP_HASH,
};
一个MAP除了需要定义其所属类型,通常还需要定义其kv的大小(BPF并不关心其实际类型,可以看作是按字节码存储)以及最大的entry数,另外还可以指定是否提前分配内存,例如BPF_MAP_TYPE_LPM_TRIE类型的map就需要在创建时指定不分配entry。
下面介绍几个比较常用的Map类型:
BPF_MAP_TYPE_HASH是大家普遍理解的kv存储的map,kv大小由用户自定义。BPF_MAP_TYPE_ARRAY是数组,只能通过int类型作为key来访问map。BPF_MAP_TYPE_PROG_ARRAY是一个特殊的存储,这个数组里存的是BPF程序。后文中我们会提到单个BPF程序限定了不能超过4096条指令,如果一个程序态复杂无法在4096条指令内完成,BPF提供了BPF_MAP_TYPE_PROG_ARRAY这个MAP来存储多个BPF程序,用户将拆分的BPF程序存入MAP中,BPF程序之间可以通过tail-call的形式来调用。BPF_MAP_TYPE_PERCPU_HASHBPF_MAP_TYPE_PERCPU_ARRAY类似于BPF_MAP_TYPE_HASHBPF_MAP_TYPE_ARRAY,只是这类map在每个CPU上都有一个map实例。在BPF中使用helper function访问这类map和非PERCPU map一致,只能访问到本CPU的map,但是用户态得到的是一个数组,用户需要自己根据CPU数来聚合值。BPF_MAP_TYPE_LPM_TRIE是字典树在BPF里的实现,通常可以用来匹配网段前缀。BPF_MAP_TYPE_DEVMAP内存储的是网络设备号,XDP程序可以将包直接转发到存储在这里的设备中,提升包转发性能。BPF_MAP_TYPE_SOCKMAPBPF_MAP_TYPE_SOCKHASH是用来存储socket的存储类型,以后会做详细介绍。
前面提到,BPF程序是用户编写然后加载到内核由事件驱动来同步执行的,所以如果程序有问题很可能导致内核的不稳定。为了确保BPF程序不影响内核正常工作,不影响执行效率,BPF严格规范了BPF程序。BPF程序的指令数不超过4096条,且程序中不能有loop以保证程序最终一定能退出。因此BPF在内核中引入了一个verify组件专门用来做程序的检查工作。实际上verify程序有很对安全检查,在BPF程序加载到内核时就会进行检查,检查的内容远不止指令条数和检测loop那么简单。例如在XDP程序类型中,每次访问包的某个索引位置之前,都需要BPF程序检查是否越界,如果没有检查,verify将会失败。所以虽然BPF程序本身可能逻辑并不复杂,在编写的过程中最好能够做到写一小部分逻辑后就编译加载到内核测试是否能通过检查,否则由于报错信息十分含糊,很难定位到错误的代码。
编写BPF程序,iovisor/bcc项目是一个很好的开始。使用这个项目,可以在python中写BPF代码直接运行,源码里有许多例子可以学习。前面提到,我们可以自己编写BPF程序,然后使用llvm+clang编译成BPF格式的字节码编译命令也十分简单,clang -O2 -target bpf -o bpf prog.o -c bpf prog.c.,然后可以使用系统调用bpf(...)来加载到内核。除了自己写代码操作BPF程序,一些工具也可以帮助我们做到这一点。例如linux源码自带的bpftool可以操作部分BPF程序和map,iproute可以将BPF程序加载到网卡,tc可以将tc相关BPF程序加载到tc。