k8s floatingip evolution
在我们内部的k8s系统的网络模式支持上,我们实现了多种网络模式的支持,最主要的就是overlay和floatingip的支持。
在k8s系统中实现floatingip网络模式的方案,最初我们采用了bridge+veth的模式,在跑容器的主机(物理机或虚拟机)上创建一个linux bridge,将原主机的网卡桥接到这个bridge。每创建一个pod,都创建一对veth设备,一端连接bridge,一端扔进容器里达到容器与外界2层可达的效果。实现模型如下图所示:
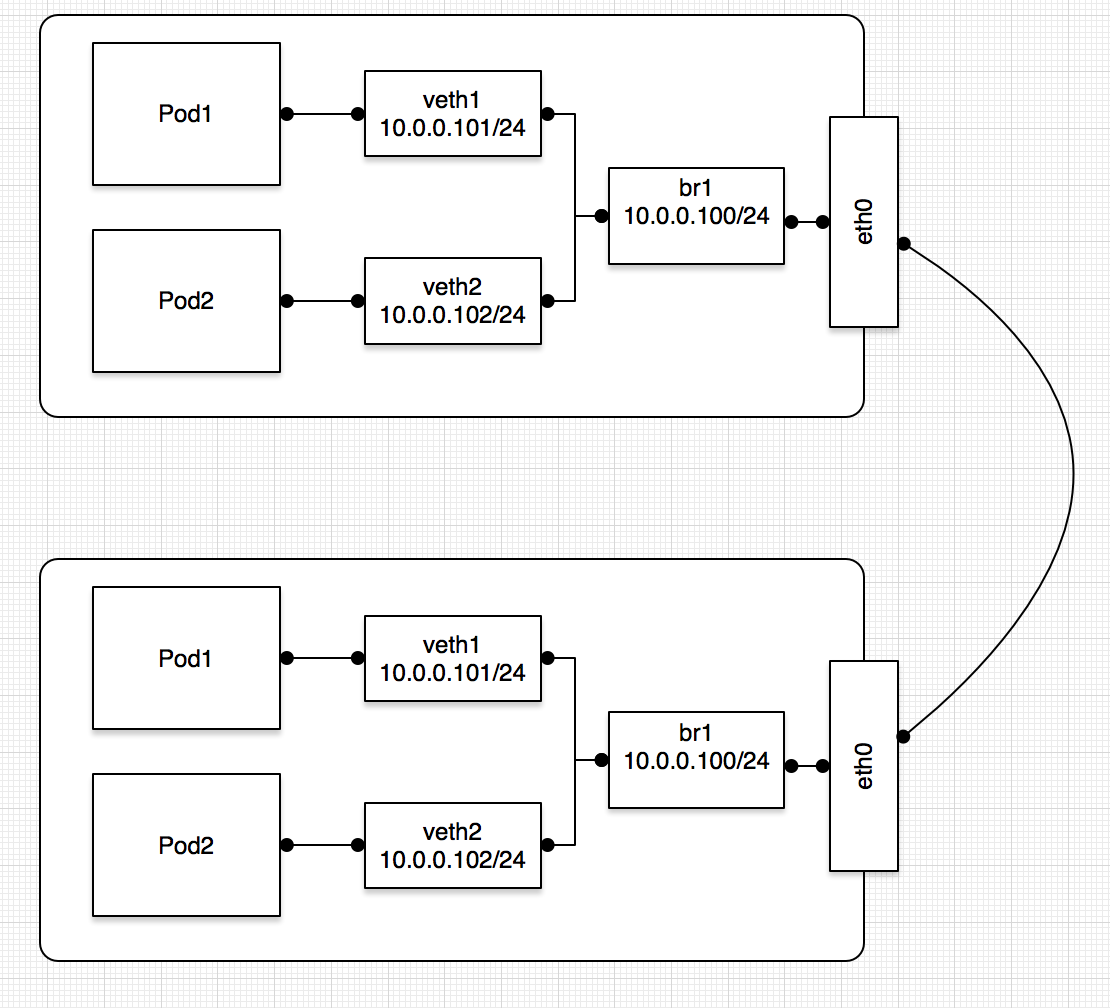
这种模式下,主机被作为一个交换机使用,包从容器发出在主机2层就决定走向,如果请求是对本机或者本机的其他容器,则走到相应网卡或进入内核网络栈,否则从原网卡流出到主机外。这种方式能够满足floatingip的pod和主机或者其他floatingip的pod互通。
但是,在k8s场景下这里有个问题。k8s对pod网络的要求是,pod之间能相互访问,pod能通过serviceIP访问对端。如果目的地址是一个serviceIP,实际是需要经过主机的iptables规则的,而iptables规则通常工作在3层,这就会导致floatingip模式下的容器对serviceIP的访问出现异常,与k8s的网络标准不符,所以理论上并没有达到k8s的网络要求。不过在一般情况下,我们的业务并没有使用到serviceIP,所以也是一种切实有效的方案且已经使用在了生产环境。上面说到iptables通常工作在3层,其实内核提供了相关的参数可以对2层的包进行3层的规则匹配,需要打开net.bridge.bridge-nf-call-iptables,不过这种方式经同事测试会有其他网络上的问题,不建议打开。
除了上面说到的serviceIP访问问题,bridge+veth模式还有一些其他问题:
- 我们的k8s集群是同时支持多种网络模式的,overlay的方案我们采用类似flannel+ipip模式。这种情况下,floatingip的容器无法访问到overlayip的容器,因为没有经过tun网卡封包就出主机了。这里也解释了上面打开
net.bridge.bridge-nf-call-iptables仍不行的原因(经过iptables转成podIP)。 - 影响主机的网卡。bridge模式下需要将原主机的ethx设备桥接到bridge上,导致主机ip会从ethx移动到bridge上。一方面对主机不是很友好,有的用户可能无法接受这种ip设备的变化,另一方面,也可能对运行在上面的其他程序造成影响。例如我们的flannel就遇到了这种问题。flannel启动的时候启动参数里填写了主机的ip或对应的设备,并据此来配置相关路由,如果ip发生了变化,路由就会出错,这也是我们在生产环境下踩出来的坑。
对于k8s网络本身而言,核心问题就是容器里的报文没有经过主机的3层(iptables规则,overlay封包)就发送出去了。如果我们能实现二层不可达的网络模式,就可以解决这个问题。所以这里需要将我们创建的bridge去掉,类似于overlay的实现模式,只用veth设备去实现网络连接。去掉bridge后,veth的主机端不会连接主机的其他设备,可以达到容器发出的包需要经过主机3层网络协议栈,在3层进行iptables的masq或者走ip隧道网卡进行ipip封包。另外,与overlay实现方案一样,我们在主机上设置一个路由,使得发往容器的包走对应的veth设备(这在bridge下是不需要的,bridge自动帮我们查到了对应mac地址的veth端)。
但是进行测试之后发现容器还是无法与外部的主机进行通信。分析原因后发现在通信之前,我们需要知道ip对应的mac地址,这时候会发出arp广播。由于我们采用3层连通方式,2层是不互通的,而arp请求需要在2层连通的广播域传播,导致在3层方案中我们无法进行arp地址解析,通信在还没开始的时候就已经失败了。为了解决arp响应这个问题,我们需要配置内核参数net.ipv4.conf.{DEV}.proxy_arp。关于这个参数的介绍可以查阅网上的资料。设置了这个参数后,容器所在主机会响应从容器里发出的arp请求,也会响应从外界发来的查询容器ip对应mac地址的arp请求,从这个角度看,这里主机就相当于一个网关的角色。
至此,容器终于可以和外界相互通信了。而且也解决了开始我们提到的serviceIP访问以及floatingip主动访问overlay的问题,并且顺带解决了问题2,因为没有引入bridge,主机原来的设备我们没有进行修改。
总结下来,这种方式相比于bridge模式的优点:
- pod之间可以通过serviceIP访问
- 在多种网络模式共存下,floatingip的pod也可以访问overlay的pod
- 不更改原网卡的配置(IP)
- 不需要打开原设备的混杂模式。外界看到的容器ip对应的mac地址其实是主机网卡的mac,不需要混杂模式也能接收发给容器的包
- 交换机mac表项没有增加。交换机看到容器ip对应的mac地址是主机的mac地址,所以mac到端口的对应不变
在使用了这种模式完成floatingip网络设置后,在新环境上新业务时又遇到了新问题。用户反馈发现在容器启动后的一段时间内无法与外界通信,需要过比较长的时间才将网络恢复。进行分析和测试后,发现如果ip在主机之间发生漂移,基本必会出现这种情况。这是由于在这段时间内其他机器都缓存了arp表项,ip对应的mac还是老的,导致交换机将包发往了错误的(原主机)端口。只有当地址老化后,重新发起arp请求得到最新的ip的mac才能正常通信。所以这里我们需要主动将最新的arp包发出去刷新arp表项,我们可以使用arping这个命令达到这一点。但是前面已经说了,容器里的arp请求并不能通往外界,所以直接在容器里使用arping工具发送arp是不行的,所以我们需要在分配容器的主机上进行这个操作arping -c 2 -A -I ethx $containerIP,但是会报错bind: Cannot assign requested address。报错信息提示很明显,因为我们尝试发送一个原地址并不是我们自己的包。为了解决这个问题,需要打开内核参数net.ipv4.ip_nonlocal_bind参数,作用就是本机程序可以绑定一个不属于本机地址的ip。测试后发现可以进行arping,floatingip漂移后也不会出现一段时间内无法通信的问题了。
这里可能的一个缺点就是包传输的效率可能受到影响,例如两个在同一主机上的Pod通信,现在包都需要经过3层查询,而原来直接在2层走bridge转发即可。
相关测试脚本
1 | aip=10.0.0.100 # floatingip |