Convolutional Neural Network
Convolutional Neural Network(CNN, 卷积神经网络)是一种特殊的MLP(多层神经网络)。它的思想主要来自于生物学。1968年Hubel和Wiesel在基于猫眼的研究发现,在视皮层存在一些复杂的神经元细胞,它们对小块的子空间十分敏感,于是提出了接收野(receptive field)的概念。这层过滤器是对整体视图空间的基于空间的过滤,所以更加适合有着较强局部关联的图片特征。对卷积神经网络最成功的例子就是LeCun的LeNet5。
卷积神经网络是一个为了感知二维形状而特殊设计的多层神经网络。这种网络结构对平移,旋转,缩放等具有高度不变性(invariance)。这种网络主要有两个特征:
1. 稀疏连接(Sparse Connection)
卷积神经网络针对局部接收野的特性,强制使用局部连接而非以往全连接的方式构建网络,从而是整个网络能够更好的提取局部特征。如下图所示,m层的神经单元只与m-1层的局部单元有连接,而这些连接具有空间上连续的特性,这能更好的帮助我们理解图像的局部特性。
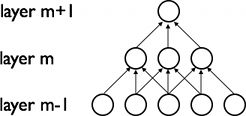
图中m层单元接收m-1层的3个局部单元的输入,所以它的接受域宽是3,m+1层相对m层也是3。但是m+1层相对于m-1层的域宽是5。这样的层堆叠起来后,会是的过滤器逐渐覆盖到全局。
2. 权值共享(Shared Weight)
在卷积神经网络中,每个过滤器(filter)Wi通过权值共享机制来覆盖整个可视域。效果如下图所示:
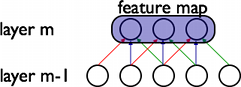
为什么需要权值共享呢?权值共享有几个好处:1, 重复单元的特征提取将不受到到绝对空间位置的限制。一旦图片的相对位置信息被提取,那么他在原图中的绝对位置就不再那么重要。2, 权值共享可以让我们更加有效的进行特征提取,因为它极大的减少了我们需要学习的变量个数。通过对神经网络规模的控制,CNN可以很好的泛化到现实中的视觉问题,这种泛化能力可能也主要来自于网络本身的两个主要特性,现在比较能够接受这一现象的原因是稀疏连接和权值共享是视觉问题的一个很好的先验知识,它使得我们的模型有了比其他深层模型更好的泛化。
完整的卷积神经网络是一个多层神经网络,每层有多个二维平面组成,每个平面由多个独立的神经元组成。网络主要由两种不同的神经元组成,分别记作S-元和C-元。S-元聚合成S-面,S-面聚合成S-层,用Us标记。C-层也是如此。网络中只有一个输入层,中间的层由S-层和C-层串联而成。
输入层是第一层,它是一个二维图像的输入。Us层被称为特征提取层,每个神经元与前一层的局部野相连接,并提取该局部的特征,Us层的每一个S-面内部的所有神经元共享突触权值,从而保持该层提取特征的invariance。Uc是特征映射层,每一个S-面都紧跟着一个C-面进行局部平均的子抽样,这种设计使得网络模型在识别图片时有了较高的畸变容忍能力。
子抽样层可以采用max-pooling方式进行抽样,这是一种非线性的下抽样方式。max-pooling可以将输入的二维平面分割成为无重叠的各个矩阵区域,对于每个子区域其输出值是该区域中的最大值。
子抽样的引入主要有一下两个方面:1,它能够有效的减少计算量。2,它提供了一种平移不变性的方式(这一点的解释暂时不是很懂)。
下图是LeNet5的网络模型:
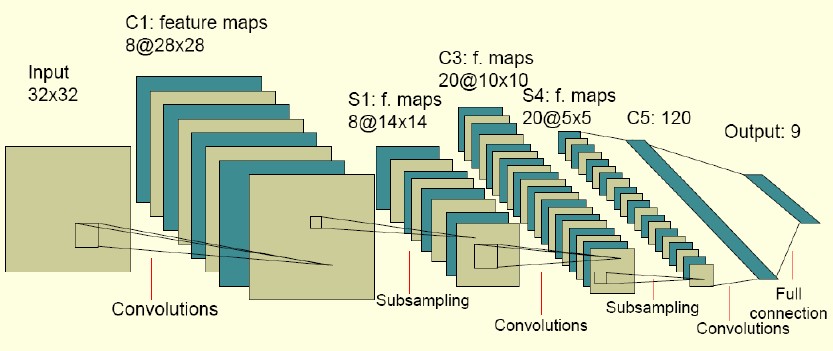
从图中可以看出,输入层是一个32*32的图像输入,然后网络按卷积和子抽样交替进行。首选卷积层由8个特征映射组成,每个特征映射指定5*5的接受域,从而得到8个S-面组成的S层,每个面28*28。接着进行一次子抽样,子抽样后的每个神经元拥有2*2的接受域。迭代卷积和子抽样后,形成20个特征映射,每个特征映射由5*5的单元组成,第五个隐藏层由120个神经元组成,每个神经元指定5*5的接受域,最后120个神经元与输出层进行全连接。图中有将近100,000个突触连接,但是只需要训练2600个参数,这极大的提高了模型的泛化能力。模型本身的参数学习可以通过反向传播进行学习。
参考文献: